Cloud-Synchronisation
Mit der WebDAV Funktionalität der Hubzilla Cloud ist es möglich die Cloud in die eigene Verzeichnisstruktur einzubinden. Das ist natürlich die direkteste Nutzung der Cloud vom eigenen Endgerät aus. Die Methode hat aber auch einen Nachteil: Wenn keine Netzwerkverbindung besteht, hat man auch keinerlei Zugriff auf die Dateien in der Cloud. Ist man offline, existieren temporär die Dateien nicht im eigenen Dateisystem.
Für Nextcloud und ownCloud gibt es ein Synchronisationsprogramm z.B. für den Desktop. Mit dieser App wird eine Kopie des Verzeichnisbaums der Cloud lokal auf dem Rechner angelegt und beide Verzeichnisse werden periodisch synchronisiert. Ändert man auf dem Rechner eine Datei oder fügt eine hinzu oder löscht eine solche, so wird das im eigentlichen Cloud-Verzeichnis auf dem Server ebenfalls getan. Das gilt für sämtliche Dateioperationen. Das lokale Verzeichnis ist also ein Spiegel, wobei die Spiegelung bidirektional ist.
Der Nachteil ist, dass der Inhalt der Cloud nun auf dem lokalen Rechner ebenfalls Speicherplatz verbraucht, der Vorteil ist aber, dass sämtliche Dateien aus der Cloud auch bei nicht bestehender Netzwerkverbindung zur Verfügung stehen. Was man lokal ändert, wird, sobald die Netzwerkverbindung wieder aufgebaut ist, auch in der Cloud synchronisiert. Das gilt auch für Änderungen die in der Cloud durchgeführt wurden.
Rclone
Eine solche App gibt es für die Hubzilla-Cloud nicht. Wobei… es gibt sie eigentlich doch: Rclone.
Das ist ein universelles Werkzeug zur Cloud-Synchronisation, das auch perfekt mit der Hubzilla-Cloud funktioniert. Es steht für Linux, macOS, Windows und BSD zur Verfügung.
Ich erläutere hier die Nutzung mit Linux, weil ich seit bald 30 Jahren nur noch Linux nutze und seit dem microsoft-frei bin und noch nie einen Mac hatte. Das Script zum Aufruf muss für Windows angepasst werden und statt Cron muss wohl der Task Scheduler genutzt werden. Wie es bei macOS funktioniert, muss ein ausreichend erfahrener Apple-Nutzer für sich beantworten.
Zunächst muss auf dem eigenen Rechner das Programm Rclone (Version >= 1.58) installiert werden.
Rclone installieren
Unter Debian, Ubuntu (und Derivate) macht man das mit
sudo apt update
sudo apt install rclone
… mit Fedora mittels
sudo dnf install rclone
… mit SuSE mittels
sudo zypper refresh
sudo zypper info rclone
…und bei Arch Linux mit
sudo pacman -Syu
sudo pacman -S rclone .
Die Konfigurationsdatei von Rclone wird in ~/.config/rclone/rclone.conf abgelegt.
Es ist empfehlenswert, diese Datei nicht selbst zu erzeugen, sondern vom Programm selbst anlegen zu lassen. Bei dieser Vorgehensweise wird das Passwort in der Konfiguration verschlüsselt abgelegt.
Rclone konfigurieren
Um Rclone zu konfigurieren ruft man es auf der Kommandozeile mit
rclone config
aufgerufen.
Nun wählt man “n” für “New remote”.
Es wird nach einem Namen für die Cloud-Konfiguration gefragt. Hier gibt man z.B “hubzilla” ein.
Danach muss der Storage Typ ausgewählt werden. Hier muss man die Nummer für den Typ webdav ausgewählt werden (unter Arch und mit Version 1.73.0 von Rclone war das die Nummer 62).
Als nächstes muss die URL der Cloud eingegeben werden. Man findet sie, wenn man im Hauptmenü (Avatarbild in der Navigationsleiste) Einstellungen ➔ Kanal-Einstellungen aufruft:
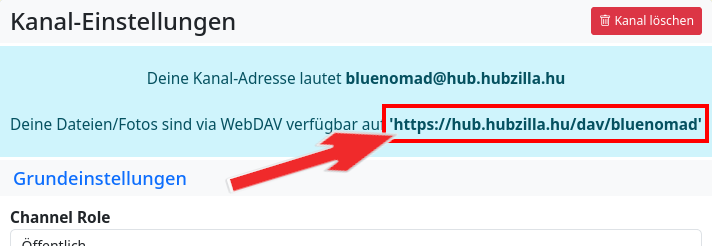
Sie hat das Schema https://<HUB_DOMAIN>/dav/<KANALNAME>.
Anschließend wird nach dem “Vendor” gefragt. Hier wählt man “other” (für generisches WebDAV).
Als nächstes muss man den Benutzernamen eingeben. Das ist der Kanal-(kurz) Name, im nächsten Schritt schließlich das Passwort (das ist das Passwort, welches man für die Anmeldung des Accounts gewählt hat).
Weitere (und erweiterte) Einstellungen verneint man, speichert die Konfiguration (“y”) und beendet das Konfigurations-Skript mit “q”.
Nun sind alle erforderlichen Daten in der Konfigurationsdatei vorhanden.
Konfiguration testen
Jetzt sollte man überprüfen, ob die Konfiguration korrekt ist, indem man im Terminal
rclone lsd hubzilla:/
ein (oder statt “hubzilla” den Namen für die Cloud-Konfiguration, die man eingegeben hat).
Es sollten nun sämtliche Order in der Cloud aufgelistet werden.
Jetzt muss noch ein Verzeichnis für die Cloud-Dateien auf dem lokalen Rechner angelegt werden:
mkdir -p ~/<VERZEICHNISNAME>
Erste Synchronisation
Für die bidirektionale Synchronisation (also lokal und in der Cloud gleichermaßen) verwendet man Rclone mit der Funktion “bisync”.
Für einen “Trockenlauf” (also dem Ausführen der Synchronisation, ohne dass Dateien tatsächlich übertragen und geschrieben werden) ruft man nun
rclone bisync <VERZEICHNISNAME> hubzilla:/ --resync --verbose --dry-run
auf (wenn als Name “hubzilla” bei der Konfiguration eingegeben wurde, ansonsten den Namen, den man sich ausgedacht hat).
Läuft dieser Probelauf korrekt durch, kann man die erste Synchronisation mit
rclone bisync <VERZEICHNISNAME> hubzilla:/ --resync --verbose
durchführen, bei der zunächst sämtliche Verzeichnisse und Dateien aus der Cloud auf den eigenen lokalen Rechner übertragen werden. Das kann, je nach Umfang der Cloud etwas dauern. Spätere Synchronisierungen umfassen nur die Änderungen und laufen blitzschnell.
Jetzt sind die Vorbereitungen abgeschlossen.
Synchronisation
Nun ist es an der Zeit, sich Gedanken über die künftige Synchronisation zu machen. Möchte man diese automatisch periodisch durchführen lassen, oder lieber den Synchronisationsprozess bei Bedarf anstoßen.
In beiden Fällen, empfiehlt es sich, die Kommandozeile für die Synchronisation in ein kleines Skript zu schreiben, welches dann aufgerufen wird:
#!/bin/bash
rclone bisync <VERZEICNISNAME> hubzilla:/ --verbose --resilient --recover
Die Datei speichert man dann z.B. unter dem Namen hzsync.sh, legt es an passender Stelle im Pfad ab (z.B. unter ~/bin) und macht das Skript ausführbar: chmod +x ~/bin/hzsync.sh.
Möchte man es nicht automatisch ausführen lassen, kann man es von der Kommandozeile aus aufrufen oder man legt sich einen Starter für die Desktopumgebung an, mit dem man das Skript dann per Klick aufrufen kann.
Für eine automatische periodische Ausführung empfiehlt es sich einen Cronjob anzulegen. Man muss sich nur Gedanken machen, in welchen Zeitabständen die Synchronisierung stattfinden soll. Durchaus sinnvoll könnte ein minütlicher Aufruf sein.
Wenn das Skript wie im obigen Beispiel unter ~/bin abgelegt wurde, erzeugt man den Eintrag in der Crontab mit
crontab -e
und gibt im Editor die Zeile
* * * * * ~/bin/hzsync.sh
ein.
Nun erfolgt die Synchronisation minütlich. Rclone legt im Verzeichnis ~./cache/rclone/bisync für den Zeitraum der Datenübertragung eine Lock-Datei an (die nach Abschluss des Vorgangs gelöscht wird). Damit wird verhindert, dass bei einer länger dauernden Dateiübertragung bereits vor Beendigung der vorherigen Synchronisation eine weitere Synchronisation angestoßen wird, was zu “Datensalat” führen könnte.